大数据文摘出品
编译:毅航、Virgil、Charlene、Jonykai、Aileen
音乐的诞生甚至早于语言,人类对于音乐的探索却从未停止。从最初的“音乐骰子”到如今火遍二次元的宅男女神“初音未来”,算法与音乐之间的故事,才刚刚开始。
算法与音乐的结合在最近几年中取得了很大进展,突然火了起来。谷歌语音助手的“人声”预约让人们大呼,谷歌AI成精了;IBM Waston创作的歌曲甚至获得了格莱美音乐奖……
人们希望借助自然的力量,更自动地创作音乐,这种想法实际上早已出现。
从某种程度上说,第一首自动生成音乐来自于大自然:中国的风铃、古希腊的风弦琴、日本的水琴窟等。
但是,算法音乐真正出现,是在17世纪的时候。有人发明了这个名叫“音乐骰子(Musikalisches Würfelspiel)”的游戏,它能通过掷骰子选择音乐片段,再合成出钢琴片曲。
?“音乐骰子”游戏示例
https://v.qq.com/x/page/h1343td3b90.html
早期的算法音乐发展史
马尔可夫链模型成形于19世纪早期,它被用于模拟概率系统,也可以用来生成全新的音乐作品。
比起骰子游戏的原理,马尔可夫链作曲在两个方面都更胜一筹:第一,马尔可夫链只需现成的音乐片段即可作曲,而不用专门谱写可互换音乐片段;第二,马尔可夫链根据音乐内容来编码音乐片段的概率分布,而非假设所有的片段具有相同的概率。
“重组中午”(Remixing Noon) ,作者为Rev Dan Catt:一条基于散文训练出的马尔可夫链的路径
Iannis Xenakis在他1958年的专辑《模拟》(Analogique)中就使用了马尔可夫链来作曲。在他的文章《合成音乐:乐曲中的思想与数学》里详细描述了每个音符的概率转移矩阵。
?第三章“马尔可夫的随机音乐:应用”(节选)
https://v.qq.com/x/page/e1343co9tml.html
《模拟A和B》Iannis Xenakis
1981年,David Cope开始利用算法作曲来解决其创作瓶颈的问题。他将马尔可夫链和其它技术(音乐语法和音乐组合学)结合成一个半自动作曲系统,他称之为“音乐智能实验”或Emmy。Davi写了论文和专利来详细描述Emmy,甚至把源码传到了GitHub上。Emmy在学习、模仿其他作曲家方面很出名。
?Emmy模仿肖邦玛祖卡舞曲的音频
https://soundcloud.com/machinelearningmusic/mazurka-after-chopin-by-david-cope
神经网络应用于音乐创作
基于一组乐谱上训练出的马尔可夫链只能产生原始数据中存在的子序列,而递归神经网络(RNNs)却可以推断出现存子序列中没有的东西。1989年,Peter M.Todd, Michael C, Mozer和其他伙伴第一次尝试使用递归神经网络生成音乐。但是由于RNN只能生成在短期内连贯的音乐,因此生成的质量一般。
?由CONCERT系统生成的三段巴赫风格的音乐
https://soundcloud.com/machinelearningmusic/after-bach-by-michael-c-mozer
2002年,Doug Eck用“长短期记忆(LSTMs)”神经元替代标准的RNN神经元,从而改进了这种方法。Doug利用该架构在一段短录音的基础上即兴创作了一段布鲁斯。他写道:“非常令人赞叹,只要有人愿意听,LSTM就能以不错节奏和恰当的构曲来演奏布鲁斯音乐。”
Doug现在在谷歌大脑带领Magenta团队,自从2016年初,他们就一直致力于开发、分享与机器学习和创造力有关的代码。Magenta已经利用Doug的基于LSTM的方法进行鼓型生成、旋律生成和复调音乐生成。他们已经构建了能够与人类演奏者一起即兴创作二重奏的系统,以及能够生成富有动感、节奏合适的复调音乐的工具。
?打开链接欣赏音乐
https://soundcloud.com/machinelearningmusic/performance-rnn-by-magenta
训练这些系统时常常遇到的难题是如何确定音乐的表示方式。编码一个RNN模型可能从文本材料的一个隐喻开始:RNN会处理一系列随着时间或空间(纸张)排列的状态(字母)序列。
但是不同于文本,音乐里的一个瞬间含义更加丰富,它可以是一个和弦,或者是各种特性的组合以此获得更好的表达。除此以外,音乐里还可能有长时间的无声或长度不一的小节。这些不同可以通过下面的方式来解决:人为构建更为合适的表示、数据增强以及设计合理的架构以保证能学习到所有的规律。
数据驱动的算法作曲所面临的另一个挑战是,用什么数据来训练?哪位音乐家的音乐有代表性?当任何自动化的创新系统需要在大量文化作品上训练时,系统往往会受那些数据量最多的文化数据的支配。
以音乐为例,巴赫、贝多芬等早期欧洲音乐大师的音乐会占音乐训练数据的大半(除了一些英国和爱尔兰民谣)。另一方面,数据是由研究人员来选取的,而研究人员们也是相对同质化的群体。
虽然LSTMs能够比标准RNN或马尔科夫链更好地保持长期一致性,但在生成短语和生成整个乐谱之间还是有差距,这一点仍需依靠手工调整。像Jukedeck, Aiva, Amper等初创公司正试图填补这种手工调整的、按需生成的公式化音乐的市场空白。
有些公司甚至已经发行了整张唱片作为营销。大公司也加入战局。François Pachet之前在索尼计算机科学实验室(Sony Computer Science Laoratories)工作,目前任职于Spotify,他研究算法生成音乐已经很长时间了,从他开发的“延续者Continuator”系统到最近的 “流动机器”Flow Machine。
https://v.qq.com/x/page/t1343jo7k5z.html
“延续者(Continuator)”旨在“利用风格一致、自动学习的音乐材料拓展音乐家的技术能力”
?打开链接观看欣赏音乐
https://youtu.be/LSHZ_b05W7o
由“流动机器”创作的《爸爸的车》(2016)是François Pachet在 Sony CSL组织的一个研究项目。“流动机器”计划去“研究和开发出能够自主或与人类艺术家合作产生音乐的人工智能系统”。《爸爸的车》的编曲、歌词和制作都由作曲家Benoît Carré完成。
尽管这些研究机构的技术都是独有的,但我们仍然可以根据它们背后的研究人员猜测出它们的关系。比如Flow Machine很可能与Continuator用的相近的方法,即比起Doug Eck更像David Cope一些。
如果对基于RNN的辅助重奏或者连续性音乐生成感兴趣,可以去看下Mason Breton的Deep Musical Dialogue或者谷歌Magenta的AI Duet。二者都是由使用者输入一段音乐,然后模型就会为你生成和谐的和声。
IBM的Watson团队开发了一个系统叫做Watson Beat可以在有限的音乐类型中基于旋律生成完整的歌曲。
?打开链接欣赏相关音频
https://soundcloud.com/ibmresearch/fallen-star-amped
上面的音乐是Watson的其他研究人员和英国歌手Alex Da Kid合作,基于从社交媒体中挖掘出的数据来为音乐寻找主题和灵感。这首曲子在格莱美还得了奖。
骰子游戏、马尔可夫链和RNN并不是唯一用程序创作音乐的方法。有一些机器学习工作者们同样尝试了hierarchical temporal memory(分层时序记忆),和principal components analysis(主成分分析)。
但我在这里更关注神经网络,因为它们是主流的研究方向。尽管这样,在神经网络里还有一些小分支被我忽略了,比如用restricted Boltzmann machines(RBM,受限玻尔兹曼机)在四小节爵士乐的小节及整首歌曲的创作,又或混合RNN-RBM模型以及混合autoencoder-LSTM models(自编码器-长短期记忆模型),还有neuroevolutionary strategies (神经进化策略)。
斯坦福学者Andrej Karpathy 在2015年5月发表博客The Unreasonable Effectiveness of Recurrent Neural Networks(RNN不讲道理地有效) 之后,RNN的威力才被众人所知道。Andrej在该文章中用了一个相对简单的神经网络叫char-rnn可以创造出十分逼真的文本,内容从莎士比亚风格的文章到C++的代码。
就如同骰子游戏在理论主义复兴和人们对数学的兴趣中火了一把一样,Andrej的文章正好在神经网络的风潮中应运而生,重新激起了人们对RNN的兴趣。一些人就把Andrej的模型应用到了音乐符号生成上。
?打开链接观看欣赏音乐
https://youtu.be/RaO4HpM07hE
由Bob Sturm创作“8个简短音乐”,用了char-rnn和23000个爱尔兰乡村音乐的谱子生成。他还领导着其它研究组织进行类似的创作。
有些人受char-rnn的启发,改变了其中的结构使得更适用于创作音乐。一些值得注意的成果有Daniel Johnson和Ji-Sung Kim。
Daniel Johnson:
http://www.hexahedria.com/2015/08/03/composing-music-with-recurrent-neural-networks/
Ji-Sung Kim:
http://www.hexahedria.com/2015/08/03/composing-music-with-recurrent-neural-networks/
Christian Walder以一种特殊的方式使用LSTM:用一个已经设计好的节奏作为起步,让神经网络去补充中间的音符。这种方法弥补了在其他模型中缺失的全局结构,但同时也限制了模型的可能性。
到目前为止,上述所有的例子都是基于音乐的符号来表示音乐的,一些爱好者们已经在想如何直接把原始的音频信号作为char-rnn的输入。
?打开链接观看欣赏音乐
https://youtu.be/eusCZThnQ-U
Joseph L. Chu作品, 在30分钟的日本流行摇滚乐队上训练
?Priya Pramesi作品,训练于Joanna Newsom的音乐。
https://youtu.be/q0ZdSAkGo48
很遗憾的是char-rnn在抽取音频信号的更高级的表示上是有天然的不足。最好的结果也只是输入数据的噪音版罢了。在机器学习里面,这种情况同“过拟合”有关,即模型在训练集上的效果很好,而对没有见过的测试集数据的效果很差。
在训练过程中,模型起初在训练集上和测试集上表现都很差,而后开始逐渐转好。但是如果训练时间过长,就会导致模型的泛化能力下降,从而发生过拟合。研究者们通常会在模型开始过拟合前停止训练。
过拟合在这种创造性任务中其实不算是一个“问题”,因为对现有音乐的重新排列也是一种创作的方式,而很难和“归纳”区分开。比如David Cope就说过“所有的音乐本质上都是灵感上的抄袭”(当然这话有点讽刺因为他自己曾被指控发表伪科学和直接的抄袭)。
2016年9月DeepMind发布了WaveNet。这个神经网络框架能够通过连续的采样抽象出出音频的高级表示。
WaveNet网络结构里用到的空洞卷积示意图
WaveNet 样本在8位数值上的概率分布
WaveNet并没有用RNN学习音频在时间上的表示,而是使用CNN,即卷积神经网络。CNN学习的是过滤器的组合。虽然CNN通常被用来处理图像数据,但WaveNet通过CNN可以用空间卷积的方式来处理时序数据。
如果我们仔细了解一下Wavenet作者们的背景,会发现很多有意思的WaveNet的先驱们。
Sender Dieleman是端到端音乐音频学习论文的第一作者,这篇文章是早期用神经网络一个样本一个样本地处理原始音频的一个应用,这里是为了做乐种分类。
Aaron van der Oord是Pixel RNN的第一作者,该文章介绍了一个可以一个像素接一个像素地生成图像
大数据文摘后台对话框内回复“音频”下载论文
Alex Graves,除了有很长时间处理演讲模型与RNN外,还在2015年做了一个如何用神经网络生成具有语义的演讲文章的讲座。
讲座链接:
https://youtu.be/-yX1SYeDHbg?t=2545
我最喜欢的是Sageev Oore用WaveNet生成了下面这首简单的钢琴曲。Sageev当时正处在为谷歌大脑工作的休假期间。
?打开链接观看欣赏音乐
https://youtu.be/xTVwYFpK5Mo
Sageev Oore在弹奏WaveNet生成的音乐
在2017年4月,Magenta项目在WaveNet的基础上创造了NSynth,这是一个用来分析和生成单声道的乐器声音的模型。他们同位于纽约的谷歌创造实验室Google Creative Lab,共同推出了一个以NSynth驱动的“音乐生产者”的实验。。
两首歌之间的线性插值与NSynth插值的对比
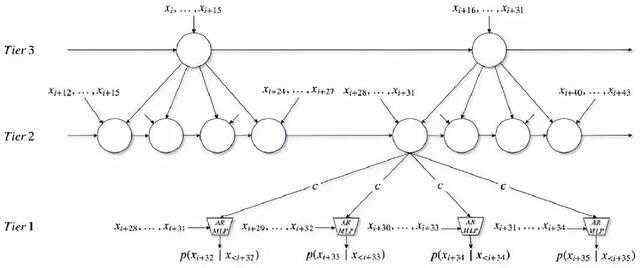
2017年2月,一个来自加拿大蒙特利尔的由Yoshua Bengio带领的团队发表了SampleRNN及其代码。它通过用一种层级结构的递归神经网络,来一段样本一段样本地生成音频。
这个研究受到了Ishaan Gulrajani的实验的影响。Ishaan曾经在原始的音频训练了一个层级结构版的char-rnn模型。
简化版的SampleRNN结构:在一个层级结构的递归网络中,第二层和第三层在更慢的时间跨度,而和神经网络相结合的第一层则在最快的时间跨度中,每一层都使用相同的上采样率(上采样率为4)
?基于同一个人的几百小时的演讲数据集训练的SampleRNN。
https://soundcloud.com/samplernn/samplernn-blizzard-mu-law-1
?根据所有的32首贝多芬的钢琴奏鸣曲训练的SampleRNN。
https://soundcloud.com/samplernn/samplernn-music-1
?由Richard Assar在32小时长的橘梦乐团(德国电子音乐先驱团体)音乐素材上训练得到的结果。
https://soundcloud.com/psylent-v/samplernn-tangerine-dream-1
SampleRNN 和WaveNet都需要非常长的时间来训练(超过一星期),并且如果不用优化的算法(比如fast-wavenet),他们会比实时生成音频的速度慢好几倍。为了减少训练和生成音频的时间,研究者们使用16千赫兹和8位数的音频数据。
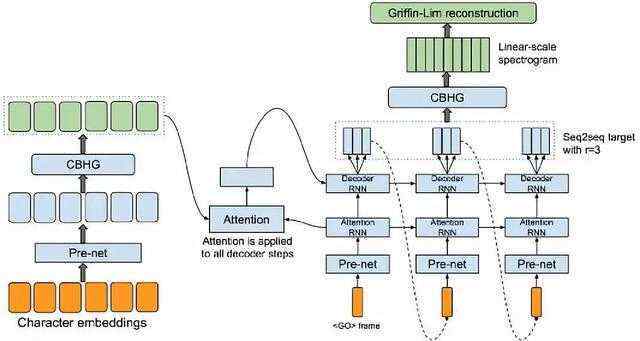
但是,对于像谷歌和百度那样的公司,音频生成主要应用在把文字变成语音,这就对生成的实时性提出了很高的要求。2017年3月,谷歌发表了Tacotron研究成果。该研究成果通过把一连串的字母或文本作为输入,谱表示作为下一步的输出,从而逐片段地产生音频。
Tacotron的结构,显示了许多技术的结合,比如注意力模型(attention),双向递归神经网络(bidirectional RNNs),卷积网络技术(convolution)等等。
Tacotron的演示样本与WaveNet的相似,仅有一些细微的差异。逐帧生成音频的一个缺点是,最后的合成依赖于Griffin-Lim相位重建法,但是这个方法并不能很好地应对多音字或者噪音的干扰。所以,这个结构被局限在了演讲音频(有可能单声道的乐器也适用,但是我还没有听说过任何的例子)。
百度在Tacotron的基础上建立了Deep Voice2研究项目,它加入了一些音频生成的后处理从而提高了声音的质量。现在有许多其他的生成演讲音频的研究,但是很少是关于生成音乐的。
这种生成音频的研究的下一步发展方向在哪里呢?
另一个正在被开发的领域是基于语料库的合成方式(离散的或连续的)与片段级的表示方法的结合。连续合成在音频合成中是非常常见的(在音频合成领域,也被称为“单元选择”) 。
这些技术在声音设计方面也有一段很长的历史,比如CataRT系统合成音色。这种基于语料库的合成方式的一大缺点是它不可能生成“一段”在原来的语料库中从来没有出现过的音频。也就是说,如果你在巴赫(德国作曲家)的所有作品作为语料库的基础上训练一个模型,并且巴赫从来没有写过C小调七和弦,那么这个模型永远不可能生成一个C小调七和弦。
尽管这个模型学习怎样生成和弦里的每一个音符,甚至学习了怎样表示对应的片段,但你还是没法通过样本音乐来合成C小调七和弦。想要解决这个问题,也许可以在逐帧的离散模型以及对音频的分解研究的交叉领域内找到突破口。
说到研究方法,我反复遇到以下两个问题。第一,我们应该使用何种声音表式呢?我们应该把音频当作成独立的样本、还是拥有大多数单声道音调内容的音频谱帧、网格里的一个音高、或者是一个声音合成器里的特征?在声音表式中,我们需要用到多少音乐领域的专业知识?
第二,我们想要怎样让这些系统互相作用?我们想要系统们从一整个音乐历史文档中学习到一个怎样的大致结果,雷同的还是标新立异的?为了生成整个音乐作品集,或者和我们即兴创作音乐?我会谨慎的对待那些声称这些问题只有一个答案的的人,如果真的只有一个答案,那么我们就需要延展我们在声音表达方面和互相作用的模式上的想象力。
我发现,如果用算法生成的音乐作品集越唾手可得,那么就越可能触发记者们的问题:“这个会让人类音乐家被淘汰吗?”通常研究者们会说他们“没有尝试替代人类”,但是他们在尝试“开发新的工具”,或者他们鼓励人类音乐家“把算法当作作品创作中的辅助工具”。把创造性的人工智能是作为“扩展”人类创造过程的一个工具可以让令人放心。
但是有没有可能,人工智能最终能从无到有地创造流行金曲,或者你最喜欢的歌?我觉得最大的问题不是人类艺术家或者音乐家会不会被人工智能替代,而是什么样的作品能被我们接受成“艺术”或者“音乐”。
可能你最喜欢的创作型歌手不能被替代,因为你需要这些和弦与歌词能够如此美妙动听的原因是有人类在其背后创作。但是当你在一个酒吧随着音乐跳舞的时候,你不需要那首音乐也一定由人类创作,因为你注意到的仅仅是别人也都在随着音乐摇摆。
虚拟歌手“初音未来”(Hatsune Miku )
除了传统模型之外,还有一个可能让生成音乐美妙动听。以电子音乐制作语音合成软件Vocaloids为引擎的虚拟女性歌手——初音未来(Hatsune Miku),已经向世人展示了,其能够召集上百万的人们来进行大众作曲并获得大量听众的收听。
音乐诞生甚至可能比语言还要早,但是至今我们依在探索音乐的所有可能性,以及创造音乐的所有方法。